
生成AIのイノベーティブな活用プロジェクト
~生成AIによる自治体長(首長)選挙の選挙公報分析を例に~
2026年06月26日 菅章、東畑佑、芦田章吾、西原史暁、吾妻洋樹、濱本真沙希、白髭龍、石井純、大塚健太
1.生成AIのイノベーティブな活用プロジェクト
2022年末のChatGPT登場を一つの契機として、生成AIの技術的発展は近年驚異的なスピードで進行している。当初はハルシネーション(事実に基づかないうそを堂々と生成してしまう現象)が大きな課題として指摘されていたが、学習手法やアーキテクチャの進化等を通じてモデルのベンチマーク精度は日を追うごとに飛躍的な向上を遂げ、そのレベルは近年では「博士号を有する専門家チームのよう」等とも表現されている。自然言語処理という枠組みから始まったこの技術は、現在ではテキスト・音声・画像・動画をシームレスに統合処理するマルチモーダル化が標準となりつつあり、象徴的なブレイクスルーが数カ月ごとに起きている状況だ。
このような状況の中、多くの組織で生成AIの導入が急ピッチで進められている。典型的なユースケースとしては、議事録・メール文書等の作成や要約、定型的資料の作成補助、翻訳、事例やオープンデータ等のリサーチ、アイデア出し・ブレインストーミング補助、社内規程の検索補助、データ処理・プログラミング補助等が挙げられるが、「生成AIのポテンシャルはこの程度のレベルにはとどまらない」というのが我々の仮説である。
そこで、既存業務の効率化・アシストにとどまらない「生成AIを使わないとできないこと」を広く検討すべく、立ち上がったのが「生成AIのイノベーティブな活用プロジェクト」である。当社のリサーチ・コンサルティング部門、創発戦略センター、調査部という3つの組織の研究員が集まり未来社会における価値を展望する「未来社会価値研究所」という場で、総勢9名の研究員が、多様なバックグラウンドを生かしてさまざまな生成AIのイノベーティブな活用アイデアを検討している。
本稿ではその中で、「生成AIによる自治体長(首長)選挙の選挙公報分析」という検討テーマについて取り上げ、生成AIの活用可能性を展望する。
2.生成AIによる自治体長(首長)選挙の選挙公報分析_検討の背景
「生成AIによる自治体長(首長)選挙の選挙公報分析」は、未来社会価値研究所の別プロジェクトである「政治人材バンクプロジェクト」とのコラボレーション企画と言うべき内容である(政治人材バンクプロジェクトの概要はプロジェクト紹介を参照いただきたい)。これまでも選挙・政治テーマに関する分析はさまざまな角度から取り組みが進められてきたが、選挙公報は特定のフォーマットがあるわけではなく、各候補者がフリーハンドで作り上げているものであり、典型的な非構造化定性データとなっているため、選挙公報の内容が選挙の動向にどのような影響を与えているのか、定量的に分析することは難しいとされてきた。
本検討では生成AIが持つマルチモーダル性に着目し、非構造化定性データである選挙公報を生成AIの活用により構造化・定量化することで、定量的な分析を行うことが可能か試行した。分析デザインの詳細について、次項で詳しく説明する。
3.生成AIによる自治体長(首長)選挙の選挙公報分析_分析デザイン
今回行った分析の全体像は図表1の通り整理される。まず、直近の無投票以外の自治体長(首長)選挙を対象として、ウェブサイト「選挙ドットコム」(https://go2senkyo.com/)に掲載されている選挙公報データ(pdf)を収集し、そのデータを生成AIに読み込ませて、選挙公報の特徴量(選挙公報を評価する軸)を生成AIに提案させた。提案内容についてプロジェクトチームで討議して、最終的に採用する特徴量を10個決定し、各選挙の各候補者について生成AIに評価させて、1行1候補者のデータベースを生成。評価結果と元となる選挙公報の内容を照らし合わせながらプロジェクトチームにて確認・調整を行い、最終的に生成されたデータベースを用いて各特徴量と当落・得票率の関係性を分析した。
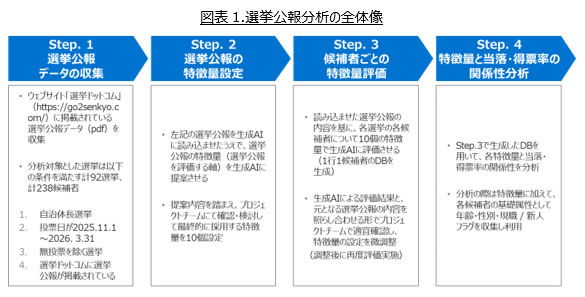
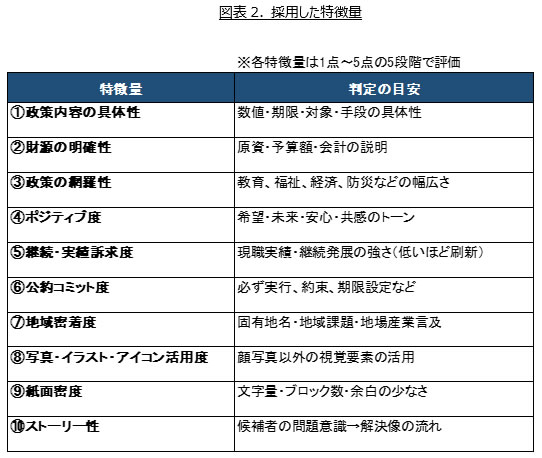
Step.2で、最終的に採用した特徴量10個は図表2の通り。選挙公報の中でどのような政策内容を語っているか、という政策面のみならず、選挙公報の中でのトーンや強調している側面、選挙公報における見せ方・デザイン等も含め、多面的な特徴量が抽出された。当初生成AIが提案した特徴量は計9分野・51個にわたっていたが(内、特に生成AIが推奨する特徴量は12個)、生成AIにインプットしていた背景情報の不足等もあり、最終的には生成AI推奨とは大きく異なる特徴量10個をプロジェクトチーム内での議論のもとで採用することとなった。この点は生成AIの限界を示す部分でもあるが、幅広く提案させて絞り込む、というプロンプト・進め方上の工夫の有効性もまた示唆されたと思料する。
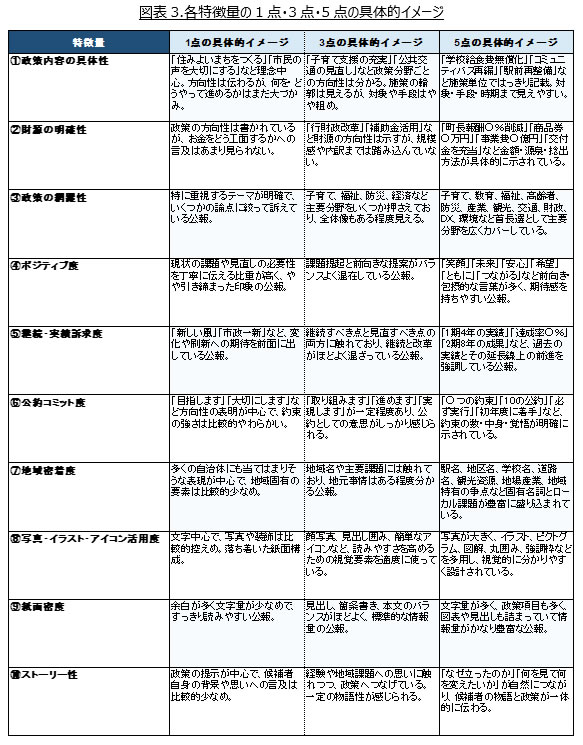
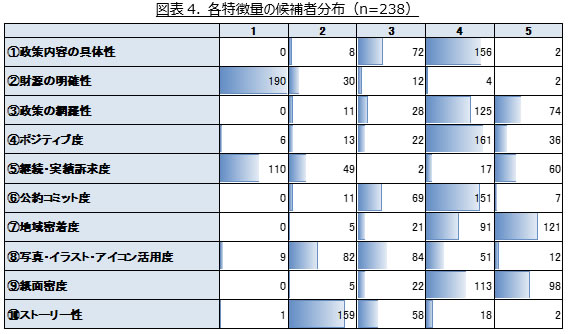
各特徴量については生成AIにより5段階で評価しており、各特徴量の1点・3点・5点の具体的イメージは図表3、各候補者の得点分布は図表4の通り。図表4が示す通り、「②財源の明確性」については選挙公報の限られた紙面で触れることが難しいこともあり、ほとんどの候補者が1~2点となっている。「⑤継続・実績訴求度」は現職においては高い(実績訴求傾向の)点が付きやすい反面、新人においては1~2点となる(刷新傾向の)ケースが多いため、2山の分布となっている。
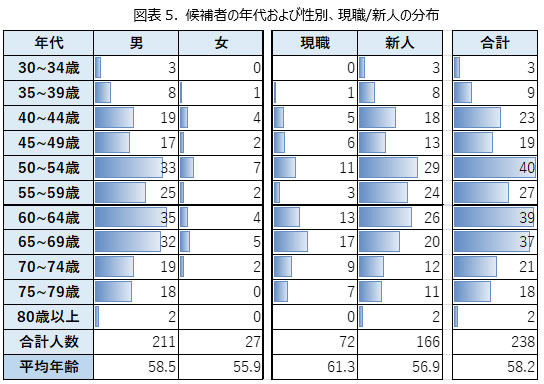
今回分析対象とした候補者は合計で238名である。238名における年齢×性別、年齢×現職/新人の分布は図表5の通り。男性が211名、女性が27名と圧倒的に男性の候補者が多い。年齢別に見ると、50~69歳の候補者が多い。現職/新人の年齢で見ると、現職の方が年齢層は高く平均年齢が61.9歳であるのに対して、新人候補者の平均年齢は56.9歳となっている。
4.生成AIによる自治体長(首長)選挙の選挙公報分析_分析結果
ここから、各特徴量と当落・得票率との関係性についての分析結果を概観する。
(ア) 各特徴量と「得票率 / 期待得票との差」との相関
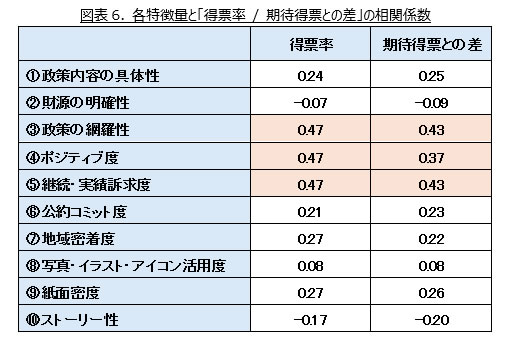
まずは全候補者に対して、「①政策内容の具体性」から「⑩ストーリー性」までの各特徴量と候補者の「得票率および期待得票(100%÷立候補者数)との差」の相関を図表6に示している。これを見ると、「得票率および期待得票との差」ともに、③政策の網羅性、④ポジティブ度、⑤継続・実績訴求度において特に正の相関があることが分かる。
(イ) 現職/新人別の③政策の網羅性、④ポジティブ度、⑤継続・実績訴求度の評価と得票率
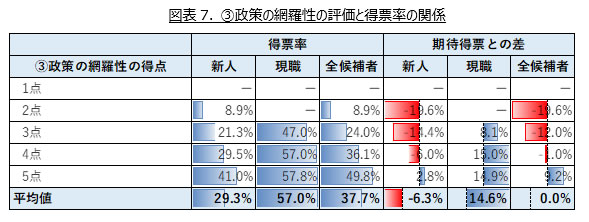
「③政策の網羅性」の評価得点ごとの「得票率 / 期待得票との差」の平均値を示した表が図表7である。全候補者で見ると、政策の網羅性に関する得点が高いほど、得票率も高いことが読み取れる。特に現職よりも新人候補者についてその傾向が強い。
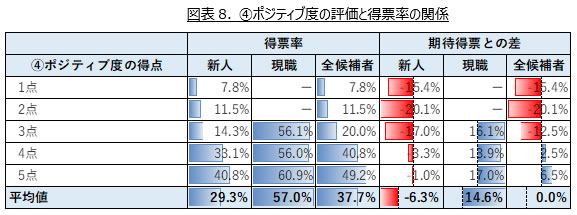
④ポジティブ度の評価得点ごとの「得票率 / 期待得票との差」の平均値を示した表が図表8である。全候補者で見ると、ポジティブ度に関する得点が高いほど、得票率も高いことが読み取れる。こちらも現職よりも新人候補者についてその傾向が強く、ポジティブ度の得点で4点以上の候補者は得票率が30%以上と比較的高い水準になっている。
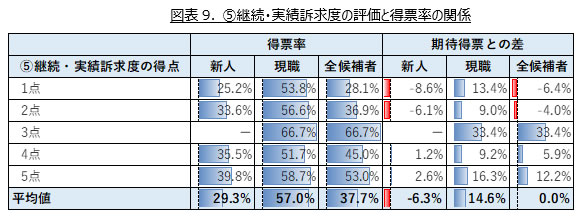
⑤継続・実績訴求度の評価得点ごとの「得票率 / 期待得票との差」の平均値を示した表が図表9である。全候補者で見ると、継続・実績訴求度に関する得点が3点の候補者の平均得票率が最も高くなっているが、それを除くと、継続・実績訴求度に関する得点が高いほど、得票率も高いことが読み取れる。
新人候補者では、継続・実績訴求度に関する得点が高いほど、得票率も高くなる傾向が読み取れるが、現職においてはどの得点でも得票率が50~60%であり大きな差がない。
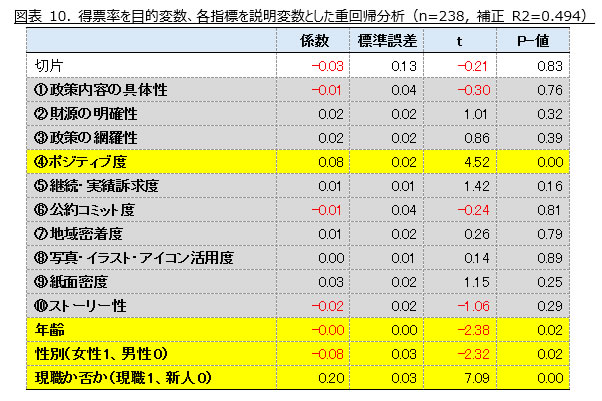
(ウ) 得票率を目的変数、各特徴量を説明変数とした重回帰分析
得票率を目的変数にとり、①~⑩の各特徴量と年齢・性別・現職ダミー変数を説明変数とした重回帰分析を実施した。有意水準5%で見ると、得票率に影響を及ぼす要因は、ポジティブ度、年齢、性別、現職か否かの4項目となった。選挙公報の記載がポジティブであるほど、得票率が高くなることが言える。
※重回帰分析とは、複数の説明変数(今回は各指標)と、1つの目的変数(今回は得票率)の関係性を定量的に推定する分析手法であり、各指標が得票率に及ぼす影響を(他の変数の影響を除いて)クリアに推定することができる。
※(偏回帰)係数は、目的変数である得票率に各指標が及ぼす関係の強さを表している。
※P-値とは、説明変数と目的変数に関係性がない場合に、この結果、あるいはそれ以上に極端な結果が偶然得られる確率である。一般的にはP-値が0.05より小さいと2変数間に関係があると解釈することが多く、この基準(0.05)を有意水準と呼ぶ。
※ダミー変数は、今回の分析における性別や現職か否かなどのようなカテゴリカルデータ(いくつかのグループに分かれるようなデータ)を分析に入れ込むために[1]とや[0]の数値に変換した変数。
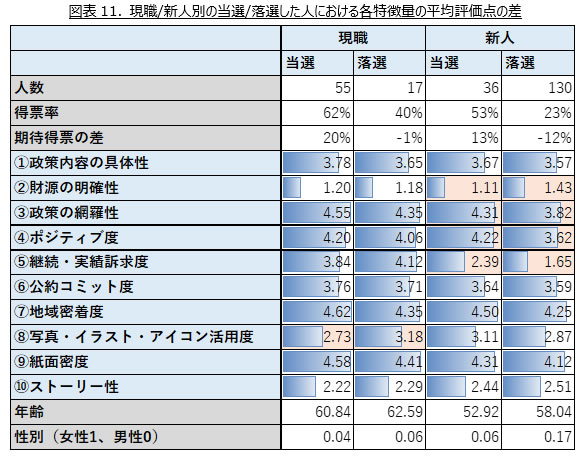
(エ) 現職/新人と当選/落選した人における各特徴量の評価の差
現職/新人それぞれにおいて、当選した人と落選した人の各特徴量の平均評価点の差(図表11)を見ると、②財源の明確性、③政策の網羅性、④ポジティブ度、⑤継続・実績訴求度、⑧写真・イラスト・アイコン活用度、で比較的大きな差(0.3ポイント以上)が見られた。
②財源の明確性については、新人の落選者のみ高い得点となっている。
③政策の網羅性については、新人の落選者のみ低くなっており、新人から当選した人は現職の政策の網羅性と同程度の得点を記録している。
④ポジティブ度については、新人落選者が低く、新人の当選者で最も高くなっている。
⑤継続・実績訴求度については、新人は現職に大きく劣る一方で新人当選者は落選者と比較して得点が高い。
⑧写真・イラスト・アイコン活用度では、現職の当選者と比較して現職の落選者は高い得点となっている。一方で、新人について着目すると、当選者の方が落選者よりも得点が高い。
5.考察
今回の分析で最も注目するべき結果は、「選挙公報のポジティブ度と得票率の間に関連が見られた」という点である。重回帰分析の結果、10個の特徴量の中で得票率との関連が統計的に有意であったのは、④ポジティブ度のみ(係数0.08、p値0.00)であった。➂政策の網羅性、➄継続・実績訴求度、は単体では得票率と相関では正の関係を示しながらも、他の変数を統制すると有意な関連を持たなかった。
各指標を詳しく見ると、いくつかの興味深い傾向が確認できる。
➂政策の網羅性
単体での得票率の相関では、正の相関(0.47)を示す。現職/新人別に見ると、新人落選者のみスコアが低く(3.82)、新人当選は現職と同様に4.00を超えるスコアを記録しているため、新人候補者にとって政策の網羅性が当落を分ける一因となっている可能性がある。
④ポジティブ度
単体での得票率の相関では、正の相関(0.47)を示す。新人落選者のスコア(3.62)が最も低く、新人当選者では最も高くなっており、現職・新人ともにポジティブ度が高い候補者ほど当選しやすい一貫した傾向が確認できる。
➄継続・実績訴求度
単体での得票率の相関では、正の相関(0.47)を示す。現職落選者(4.12)が現職当選(3.84)を上回るスコアを記録しており、一見すると「実績アピールが逆効果」に見える。また、新人全体では現職に大きく劣るスコアであるが、新人当選者(2.39)は落選者(1.65)と比較して高いスコアを示している。
ただし、結果の解釈は慎重に行うべきである。まず、➂政策の網羅性、➄継続・実績訴求度が複数の指標を統制した重回帰分析で有意性を失う背景には、➂ポジティブ度が第3の変数として機能している可能性がある。政策を網羅的に書く候補者や実績を丁寧に訴求する候補者は、そもそも前向きなトーンで公報を書く可能性があるとすれば、重回帰分析でポジティブ度を統制した際に、これらの指標の有意性が消えるのは自然な結果と言える。つまり、これらの指標と得票率の関連は、ポジティブ度との連動によって生じていることも考えられる。
また、➄継続・実績訴求度における現職落選者のスコアの高さについては、逆の因果が働いている可能性も考えられる。劣勢に立たされている現職ほど実績を強調せざるを得ない状況にあるという仮説だ。「実績を訴えるから負ける」のではなく、「負けそうだから実績を訴える」という構造である。
結局のところ、これらの考察が収束するのは、「得票率と強く関連するのはポジティブ度である」という結果である。政策の具体性や網羅性といった「内容」ではなく、前向きなトーンという「伝え方」の方が得票率に寄与するという結果は、有権者が政策の論理的な評価だけで投票先を決めているわけではない可能性も示唆する。しかし、注意して認識しておくべきなのは「ポジティブに書けば票が増える」と断言するためにはさらなる検証が必要であることだ。「もともと勝てる立場にある候補者ほど余裕をもってポジティブな選挙公報を書ける」という逆の因果も考えられる。今回の結論はあくまで「ポジティブな選挙公報を書く候補者が当選しやすい傾向がある」にとどまる方が健全だ。
本分析の限界として、ポジティブ度と得票率の関連が候補者に関する測定できていない要因(知名度・組織票等)によって説明される可能性を排除できていない点が挙げられる。この点を検証するためには知名度や組織票といったデータを追加変数として加えた上で分析を行う必要がある。また、複数回選挙に出馬している候補者のデータを収集し、同一候補者が選挙公報のトーンを変化させた際に得票率がどのように動くのかを追う分析も実現できれば、より因果関係に近い検証が可能となる。こうした追加的な検討を積み重ねることで、今回の分析結果の解釈を確かなものにできるのではないだろうか。
今回の取り組みの本質的な意義は、選挙や政治といった特定の文脈にとどまらず、より普遍的なデータ活用の可能性を示した点にある。 従来のデータ分析は、売上や費用などの「構造化された定量データ」の取り扱いを前提としていた。一方で、文章や画像、インタビューなどの「定性データ」は体系的な解釈が難しく、性質上構造化もされていないケースが多いため、担当者の経験や勘に依存しがちであった。そのため、分析者によって解釈が変わり得るという構造的な限界があり、客観性や体系性に課題が残されていた。また、統一的な尺度で定性データを定量化・構造化しようとしても、膨大な時間とコストがかかるため、大量のデータを処理することは現実には困難であった。
生成AIは、この構造を根本から変革する。今回の取り組みが証明したように、生成AIを活用すれば、膨大なテキスト情報を体系的な評価軸で迅速に定量化・構造化し、統計分析に組み込むことが可能となる。これにより、従来の構造化定量データに非構造化定性データを融合させた客観的な分析を、現実的なコストと時間で実現できるようになる。その応用領域は極めて広い。例えば、顧客アンケートの自由記述から購買意欲の強度を数値化する、競合他社のウェブサイトと自社サイトを比較評価する、あるいは営業提案書のトーンや訴求力を客観的にスコアリングする、といった活用が挙げられる。これらは、従来であれば担当者の経験や勘に頼らざるを得ず、定量化・構造化して扱うには多大な時間とコストを要するデータであった。しかし生成AIの導入により、そうした高度な分析であっても、客観的かつ低コストで実現することが可能となる。
今回の選挙公報分析は生成AIという新しい道具を手にした私たちが「何ができるようになったのか」を示す一つの実例である。非構造化定性データという領域に分析の光を当てることで、私たちの業務における意思決定の質と幅は大きく広がる。今後もこのような実証的な取り組みを重ねながら、生成AIの実践的な可能性を探求していきたい。
※記事は執筆者の個人的見解であり、日本総研の公式見解を示すものではありません。