
オピニオン
「マルチモーダル化」「エージェント化」により進化するAIの将来展望 と社会実装に向けた論点
2025年11月13日 大迫拓矢
1 はじめに
AIは一般的には「人間の思考プロセスと同じような動作をするプログラム全般」として定義される。AIは関連する多数のデータを読み込みインプット・アウトプットの関係性をAIモデルに学ばせる「学習」フェーズ、学習したAIモデルがインプットを受け取り、アウトプットを返す「推論」フェーズの2段階で情報を処理する。これにより、あたかも人間のように文脈(コンテキスト)や周辺情報を踏まえて柔軟に処理することや、曖昧な情報を判断することができる。
AIはこれまで幾度かの技術的なブレイクスルー・社会的なブームを繰り返しながら、徐々に我々の社会に浸透してきた。特に近年の生成AIブームにより、AIは単なる技術要素ではなく社会のあるべき姿/将来像にまで影響を与え得るビッグワードとなっている。本稿では技術視点での将来展望および、AIの社会実装に向けて顕在化している課題について解説する。
2 AIの将来展望と進化の方向性
今後のAIの進化の方向性を理解する上では、「マルチモーダル化」「エージェント化」がキーワードとなる。
2.1 マルチモーダル化
「マルチモーダル(Multimodal)化」とは、AIに複数の異なる種類の情報(画像+テキストなど)を組み合わせてインプットし、学習させる手法である。これにより、AIはより深く文脈を理解するだけでなく、単一の情報源だけでは判断が難しい異常値・外れ値の検出も可能となる。人間が五感を通じて得た複数の情報を踏まえて判断を下すのと同様に、AIにも多様な情報を与えて学習させることで、より人間に近い複雑な判断・処理を行うことが可能となる。近年では、インプットに加えアウトプットのマルチモーダル化も進展しており、テキストからアニメ調の画像を生成するなど、AIの適用範囲はますます拡大している。
マルチモーダル化は今後、自動運転・ロボティクスなどのAIがセンサー・カメラなどのインプット情報により外の世界を認識し、次に行う物理的な行動を判断する分野(フィジカルAI)が主戦場になると考えられる。特に、自動運転ではセンサー・カメラ情報と車両制御(≒ハンドルの操作)をインプット・アウトプットとして直接ひもづけることでさまざまな道路状況や交差点・歩行者有無などの複雑な環境に対応することができるEnd-to-End自動運転モデル(※1)が注目されている。自動運転向けAIの開発加速に伴い、画像処理やモデル軽量化などの要素技術が進展し、AIの新たなブレイクスルーが起こる可能性がある。
2.2 エージェント化
従来のAIには、あくまでアウトプットとして処理・判断の結果を出力することまでが求められており、以降は人間や別のシステム・機械がAIの処理・判断結果を受けて意思決定を下し、アクションを実行することが前提であった。「エージェント化」ではAIの機能を意思決定やアクションまで拡張することが目指されている。例えば、投資活動においてはAIが市場環境を分析し、どの銘柄にどれだけの投資を行うべきかを判断するだけでなく、その先の市場取引までを自律的に実行する。プログラミングではAIによるコードの補完・バグ修正(Copilot)に加え、AIがコードを自動で生成し、自律的に実行・改善するような次世代のサービス(Devin(※2)、Replit(※3)など)が登場している。
「エージェント化」はマルチモーダル化を含めたAIの情報処理能力の向上および、API/プラグインなどの外部との接続性の向上を契機に近年急激に発展を遂げた。具体例として、Open AIが2025年7月にリリースした「ChatGPTエージェント」(※4、※5)を取り上げる。「ChatGPTエージェント」では、利用者がタスク(「XX日にXX市のホテルを予約して」、「XXさんにXXの件名でメールを送信して」など)を指示すると、AIが行動計画を生成し、ブラウザ内の仮想コンピュータを操作しながら逐次的に処理を行うことで与えられたタスクを実行することができる。これまでの対話型のAIサービスとは異なり、以下の3つの機能が加わることで意思決定・アクションにより踏み込んだサービス提供が可能となっている(※6)。
・あらかじめ行動計画を立て複数の処理を逐次的に実行する機能
・仮想コンピュータ画面の内容を言語として認識する機能
(画像⇒テキストへの変換)
・Gmailなどの外部サービスとの接続機能
(ユーザーの事前認証により外部サービスとスムーズに連携することが可能)
「エージェント化」は、単独のAIサービス(GPT、Geminiなど)を基盤として他のサービスをつなげることを念頭においたサービスを主に対象としている。一方で、近年はユーザーが処理ごとに複数のAIサービスをモジュール的に組み合わせて活用することで一連のタスクを実行するような「AIオーケストレーションサービス」(Dify(※7)、LangChain(※8)など)も登場しており、AIを活用したアプリケーションは今後もさらに多様化・複雑化していくと考えられる。
もっとも、AI業界はまだ投資依存の段階であり、アプリケーション/サービスの提供を通じて持続的な収益を得る「正の循環」を確立するには至っていないのが実情である。しかしながら、アメリカ/中国などを中心に安全保障の観点からAIへの投資を国家戦略として位置付ける動きが加速しており、AIはもはや単なる民間ビジネスの枠を超えた存在となっている。こうした背景を踏まえると、今後もAI業界が官民双方から十分な投資を受け、技術発展が進行することが大きく期待できる。従って、進化を続けるAIをいかにして社会に適切に組み込んでいくかが今後の重要な論点になる。
3 AIが浸透した社会にて表面化する課題
AIの社会実装を議論する上では、技術だけでなくユーザー・開発者・インフラなどのAIを取り巻くエコシステム全体を俯瞰し、それぞれの立場でどのような課題が起きているか、起こり得るかを想定する必要がある。
AIに関連するプレーヤーは、AIサービスを利用する「AIサービス利用者」と、AIを搭載したソフトウェア・アプリケーションなどのサービスを利用者に提供する「AIサービス事業者」、AIサービス事業者に対してGPU/サーバーなどのサービス開発・運用に必要なインフラを提供する「AIインフラ事業者」に大別される。
下図表に整理した通り、「AIサービス利用者」「AIサービス事業者」に関する課題も重要ではあるものの、利用者のAIに対する理解や政府ガイドラインの整備などが進むことで時間をかけて解決されるものがほとんどである。他方で、「AIインフラ事業者」に関する課題は国内のAI利用拡大・産業発展に向けてより早期に解決を図る必要がある。そのため、以降は「AIインフラ事業者」に焦点をあて、主要な課題を2つ解説する。
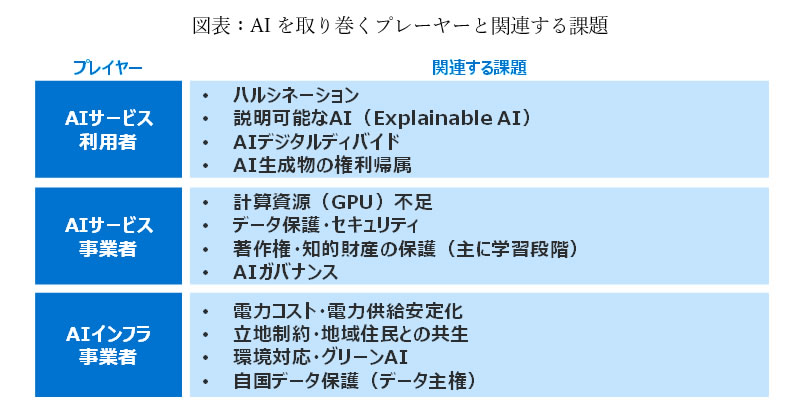
3.1 立地・電力供給に関する課題
AIインフラ事業者が直面している課題の1つは、データセンター(DC)の立地と電力供給に関するものである。立地と電力供給は密接に関連するため、ここでは両者をまとめて議論する。
AIは学習の段階で大量のデータをモデルに読み込ませる必要があり、その過程で大量の電力を消費する。米AIベンチャーHugging Face社などの共同チームが発表した研究では大規模言語モデル「BLOOM」が言語を学習する際に消費した電力量は433MWhであり、平均的なアメリカ人家庭が消費する41年分の電力量に相当する(※9、※10)。またモデルが構築した後の段階も、利用者にAIアプリ・サービスを提供するために推論として計算が行われ、定期的なモデルアップデートも必要となる。従って、AIのための計算が行われるデータセンターには長期的に安定した電力供給を行う必要があり、そのことは電力インフラが整う都心部(東京・大阪)近郊にデータセンターが集中している要因の一つにもなっている。
近年は、政府・自治体による支援や風力・太陽光発電などの再生可能エネルギーとの連携が容易であることから苫小牧(北海道)などの地方部にデータセンターを新設する動きがあり、AI学習用途を中心にデータセンターの地方分散が進むとみられる。一方で、AI推論の中にはスマートフォン・PCなどのアクセスする端末の近傍にデータセンターを配置し、通信による遅延を最小化することが必要なアプリケーションも存在する。従って、全てのデータセンターが地方に流れるのではなく、今後数年~10年程度にかけてAI学習/推論に必要なデータ量に合わせて、データセンターの国内での立地最適化が進むとみられる。
3.2 データ主権に関する課題
AIインフラ事業者に関する別の課題としてデータ主権に関する問題を取り上げる。データ主権とは「国や地域が自国のデータに対する管理権を持つこと」を指し、AIサービスを提供する上でのデータの流れが国際的に問題視されている。
AI学習・推論を行う(≒データが蓄積される)データセンターの保有者はAIインフラ事業者であることが多く、主に以下の3つの保有パターンに分かれる。
①AIサービス利用者(企業・自治体など)が自身で保有する場合
②AIサービス提供事業者(OpenAIなど)が保有する場合
③AIインフラ事業者(AWS/Microsoftなど)が保有する場合
うち①の場合はAIサービス利用者がデータセンターの設置地域を管理することができる一方で、②・③の場合はどこのデータセンターで学習・推論を行うか、どこに学習のためのデータを保管するかなどの意思決定が他者に委ねられており、ある国のユーザーに関するデータが別の国のデータセンターに転送されて学習などが行われる可能性がある(※11)。特に主要なAIインフラ事業者やAIサービス提供者が保有するデータセンターはアメリカを中心とした自国外に設置されることが多く、国際競争において重要な戦略的資源となりつつあるデータが海外に流出するリスクが高い状況にある。
そのため、「データ主権」はAIインフラ事業者のみならず国として対応すべき課題であり、各国で越境データ流通に関するルール形成が進められている。例えば、EUの一般データ保護規則(General Data Protection Regulation:GDPR)や中国のデータ越境規制ではいずれもデータの保管場所や取り扱い手法に一定の制限を設けている。日本においても個人情報保護委員会にて生体データの取り扱いや個人のオプトアウト強化などに関する議論が進められているものの、越境データ規制に関しては議論が限定的となっている(※12)。今後起こり得るリスクに対して早期に制度面での検討を進めることが求められる。
4 最後に
AIのような新しいテクノロジーは人々の生活を豊かにする一方で、その豊かさによって従来の社会では表面化しなかった新たな課題を生み出すことがある。これは、インターネット・スマートフォンなどの過去のテクノロジーの社会実装の歴史からみても明らかである。
まだ、技術発展の途上である今だからこそ起こり得る課題に対してどのように対策をしていくべきか、国として、そして社会として議論を進めるタイミングに来ていると考える。
(※1) Turingウェブページ
 (参照2025年10月30日)
(参照2025年10月30日)(※2) Devinウェブページ
(参照2025年10月30日)(※3) Replitウェブページ
(参照2025年10月30日)(※4) Open AI「ChatGPT エージェントが登場:研究とアクションをつなぐ新たな架け橋」
(2025年7月)(参照2025年10月30日)(※5) ChatGPTエージェントはウェブサイトとの対話機能「Operator」(2025年1月にリリース)と情報統合機能「deep research」(2025年2月リリース)を組み合わせて運用されている。
(※6) 日本総合研究所先端技術ラボ「AIエージェントが顧客になる日~自律型AIへの販売戦略を考える」
 (2025年3月)(参照2025年10月30日)
(2025年3月)(参照2025年10月30日)(※7) Difyウェブページ
(参照2025年10月30日)(※8) LangChainウェブページ
(参照2025年10月30日)(※9) Alexandra Sasha Luccioni et al. 「ESTIMATING THE CARBON FOOTPRINT OF BLOOM, A 176B PARAMETER LANGUAGE MODEL」
(2022年11月)(参照2025年10月30日)(※10) Nestor Maslej, Loredana Fattorini, Erik Brynjolfsson, John Etchemendy, Katrina Ligett, Terah Lyons, James Manyika, Helen Ngo, Juan Carlos Niebles, Vanessa Parli, Yoav Shoham, Russell Wald, Jack Clark, and Raymond Perrault, “The AI Index 2023 Annual Report,”
AI Index Steering Committee, Institute for Human-Centered AI, Stanford University, Stanford, CA, April 2023.(参照2025年10月30日)(※11) ③ではユーザーがクラウドサービスプロバイダーにオプションとしてリージョンを指定する(例:日本East、日本Westなど)ことで、他国へのデータ流出を回避することができる
(※12) 個人情報保護委員会「個人情報保護法 いわゆる3年ごとの見直しに係る検討の中間整理」
(2024年6月)(参照2025年10月30日)※記事は執筆者の個人的見解であり、日本総研の公式見解を示すものではありません。